

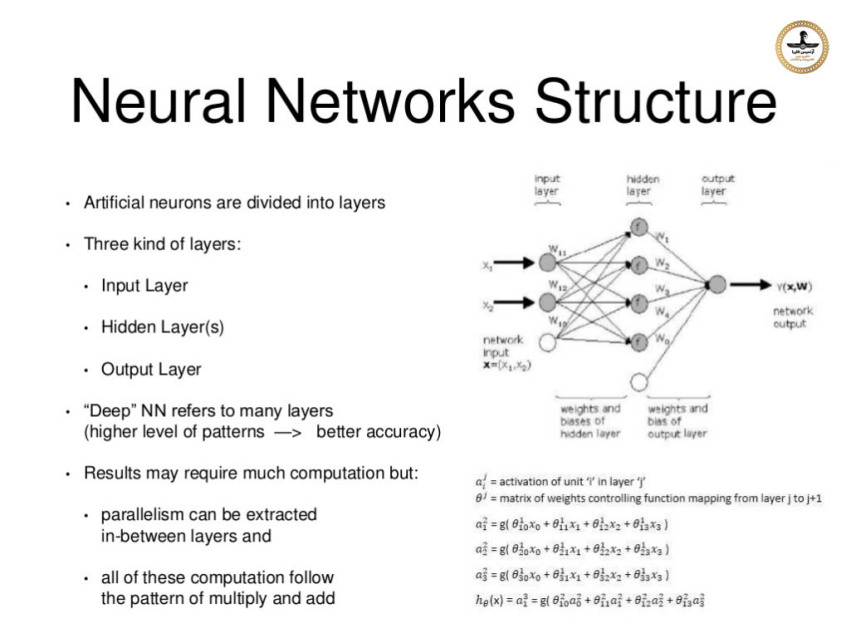
Google's TPU
Google’s Tensor Processing Unit
بررسی واحد پردازش تنسور گوگل
فراگیری ماشین
شرح کوتاهی بر تنسورفلو
تنسورفلو یک کتــابخانه و مجموعه ای رایگـان است از نرم افزارهای متن باز (منبع آزاد)
برای ایجـاد گردش اطلاعـات و برنـامه نویسی های گونـاگون برای طیف وسیـعی از
کارها. در حقیقت می تـوان گفت که یک کتـابخانه ریـاضی نمادین است که از آن
همچنین بـرای بـرنامه هـای هوش مصنوعی ، یادگیری ماشینی (فراگیری ماشین)
مانند "شبـکه های عصبی" استفـاده می شود.گوگل از تنسورفلو هم برای تحقیق
و هم بـرای تـولید بصورت جدی بـهره می بـرد. اولین بـار تنسورفـلو تـوسط
کارگروه "مغز گوگل" (Google Brain) بـرای استفـاده داخلی گوگل در تاریخ
نهم نوامبر 2015 سـاخته شد و تحت مجوز Apache 2.0 منتشر شد. ولی
شروع پـــروژه در سال 2011 بود زمانیکه واحد "مغز گوگل" DistBelief
را به عنــوان یک سیستم "فراگیـری مـاشین" اختصـــاصی مبتنی بر
شبکه های عصبی و یــادگیـری عمیق ساخت ، سپس استفاده از
آن به سـرعت در شـرکتهــای زیـر مجمـوعه شـرکت "آلفـابت" که
مدیریت گوگل و سایر شـرکتهــای موازی رابعهده دارد گسترش
پیدا کـرد و در بـرنـامـه هـای تحقیقـاتی و کــاربـردهای تجـاری
هر دو بکار گرفته شد. گوگـل چنـدین دانشمند رایانه ای از
جمله جف دین را موظف کرد تا پایگـاه داده DistBelief را
به کتابخانه ای با کاربرد سریعتر و کارآمدتر تبدیل کنند
که دست آخـر تبـدیل شـد بـه TensorFlow . در ســال
2009 ، این کارگروه به سرپرستی جفری هینتون ،
فعالیتهایی برای تعمیم دهی الگوریتم های خاص
کـه مورد استفـاده در فـراگیـری مـاشین هستند
بنـام "انتشــار پشت پــرده" انجام دادند که باعث
شد شبکه های عصبــی به دقت قابل ملاحظه بالاتری
دست یابند. به عنوان مثـال کـاهش 25٪ خـطا در تشخیص
گفتار. تنسـورفلو در واقع دومین نسـل سیستم هـای ســاخته شـده
توسط کـارگـروه "مغز گـوگـل" است. نسخه 1.0.0 در 11 فوریـه 2017 منتشر
شد. در حالی که نمونه مرجـع اولیـه تنها روی دستگاههایی بـا پـردازش منفرد اجرا
می شد ، تنسورفلو می تواند بر روی چندین پردازشگر محاسباتی و گرافیکی (CPU و GPU)
(با نسخه هــا و شــاخـه های مختلف و اختیــاری از هستــه هـــای پــردازشی CUDA و SYCL بمنظور
استفــاده در محــاسبــات عمـومی و یـا در واحـدهای پـردازش گرافیکی) اجرا شود. تنســورفلو در نسخه های
متفاوت و قابل استفاده در سیستم های عامل گوناگون بمانند لینوکس 64 بیتی ، MacOS ، ویندوز و پلتفرم های
محــاسبـاتی موبــایل مانند سیستم عــامل هـای رایــانـه ای Android و iOS موجـود است. معمـاری انعطاف پذیر آن امکان
استفاده آسان از آن را در انواع سیستم های محاسباتی و پلتفرم های گوناگون شامل انواع مختلفی از (CPU ، GPU ، TPU) ها
و از رایانه های رومیزی "دسکتاپ" گرفته تا "خوشه های رایانه ایی" و سرورهای مختلف و انواع دستگاه های تلفن همراه و دستگاه های
"تــولید کننده اطـلاعات و داده ها در لبـه تـــولید"را فـــــراهم می کنــد. در دســــامبر سال 2017 ، توســعه دهنـــدگـــان و تــولید کنندگـــان مطرحی
همچون Google ، Cisco ، RedHat ، CoreOS و CaiCloud در یک کنفــرانس ، Kubeflow را معــرفی کــردند. Kubeflow اجــازه بهــره بــرداری و استقـرار
تنسورفلو را در Kubenetes می دهد در ادامــه در مـارس 2018 ، گوگــل نسخه TensorFlow.js که نسخه 1.0 برای یادگیری ماشین در جاوا اسکریپت است را
عرضه کرد و سپس در ژانویه سال 2019 ، گوگل TensorFlow 2.0 را رونمــایی کـرد (که در سپتامبر 2019 رسماً در دسترس قرار گرفت) و در ماه مه سال 2019 ، گوگل TensorFlow Graphics را برای یادگیری عمیق در گرافیک رایانه معرفی نمود.
واحد پردازش تنسور - TPU
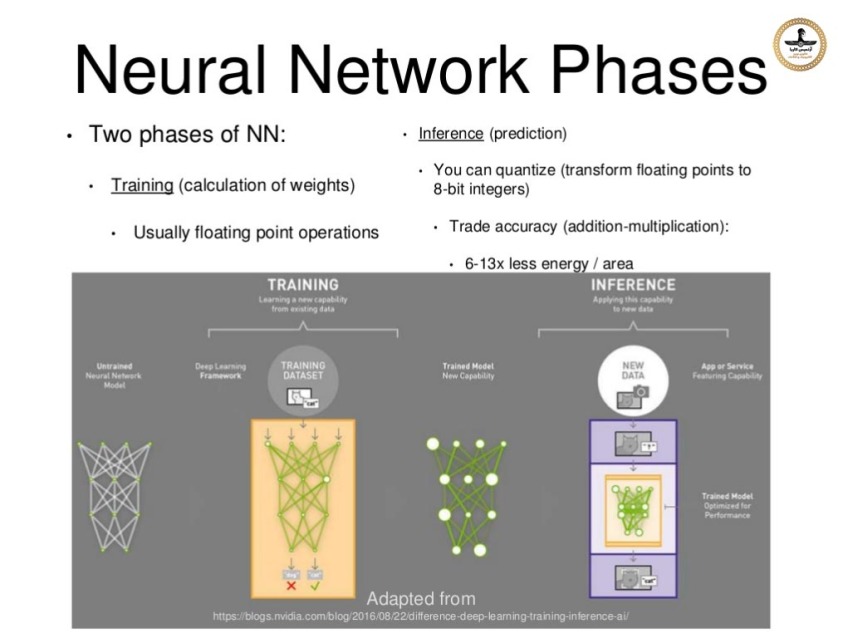
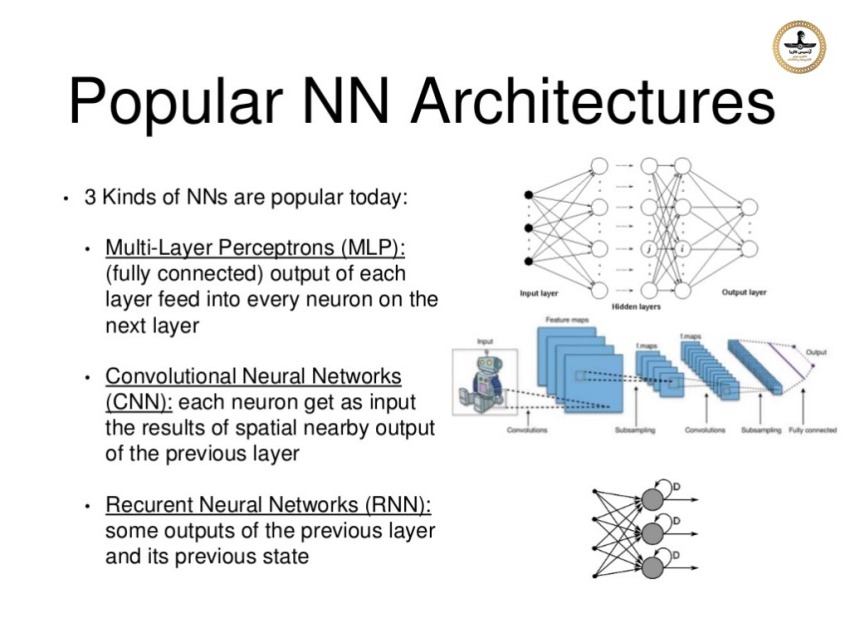
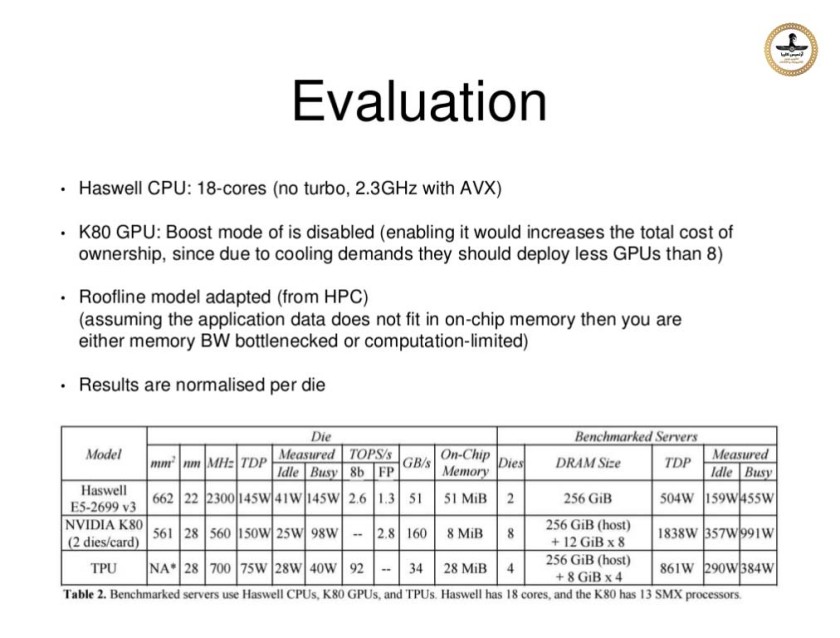
در ماه مه سال 2016 ، گوگل از یکی از دستاوردهایش یعنی "واحد پردازش تنسور" (TPU = Tensor Processing Unit) خبر داد ، این TPU بر اساس روش "مدار یکپارچه اختصاصا برای برنامه کاربردی خاص" یا ASIC = Application-Specific Integrated Circuit ساخته شده است که به طور خاص برای "فراگیری ماشین" طراحی و تولید شده و متناسب با تنسور فلو می باشد. TPU یک شتابدهنده قابل برنامه ریزی هوش مصنوعی (AI) است که به منظور فراهم آوردن توان بالای ریاضی با دقت کم (به عنوان مثال ، 8 بیتی) طراحی شده است و گرایش آن بیشتر به سمت مدلهاست تا به آموزش سیستم تشخیص. گوگل اعلام کرد که بیش از یک سال است که TPU ها در مراکز داده اش بشکل عملیاتی در حال کار هستند و آنها را برای ارائه راندمان بالاتر در مصرف توان در حوزه "فراگیری ماشین" بهینه سازی کرده بود.

در ماه مه سال 2017 ، گوگل از نسل دوم پردازنده های تنسورفلو خبر داد و همچنین اعلام کرد که از آنها در موتورهای محاسباتی گوگل استفاده می کند. TPU های نسل دوم دارای راندمانی برابر با حداکثر 180 ترافلاپ هستند . و در صورتیکه بشکل خوشه های 64 تایی سازماندهی شوند ، قدرتی برابر با 11.5 پتا فلاپ را بنمایش می گذارند. در ماه مه سال 2018 ، گوگل اعلام کرد TPU های نسل سوم عملکردی برابر با 420 ترافلاپ داشته و با حافظه ای به پهنای باند 128 گیگابایت کار می کند (دارای فناوری HBMهستند).
انتظار می رود "واحد پردازنده تنسور - TPU" نسخه سوم راندمانی بالاتر از 100 پتافلاپ ارائه دهد و با حافظه ایی با پهنای باند 32 ترابایت کار کند. در فوریه 2018 گوگل اعلام کرد که از TPU ها در نسخه بتای "پردازش ابری گوگل - Google Cloud Platform" استفاده می کند.
تشریح "واحد پردازش تنسور - TPU - نسخه یک
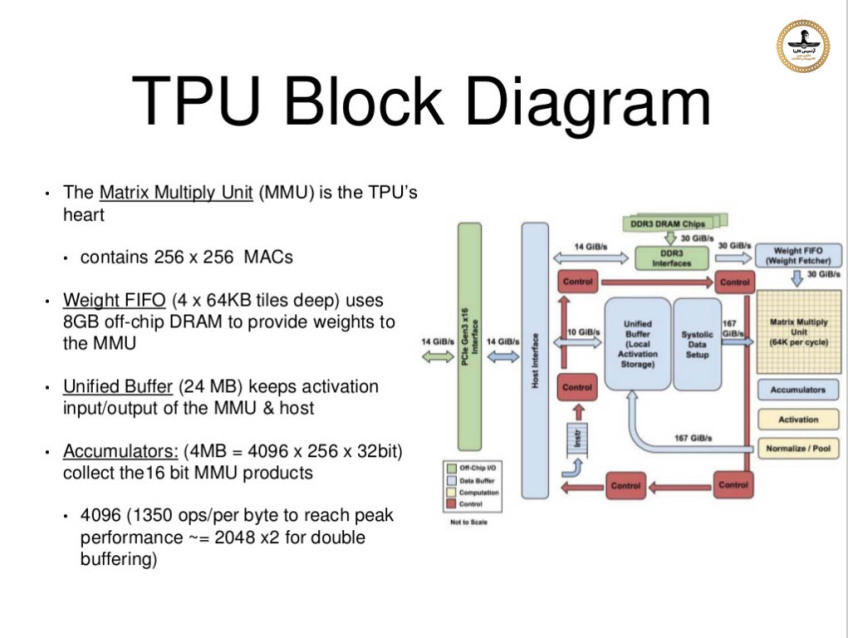
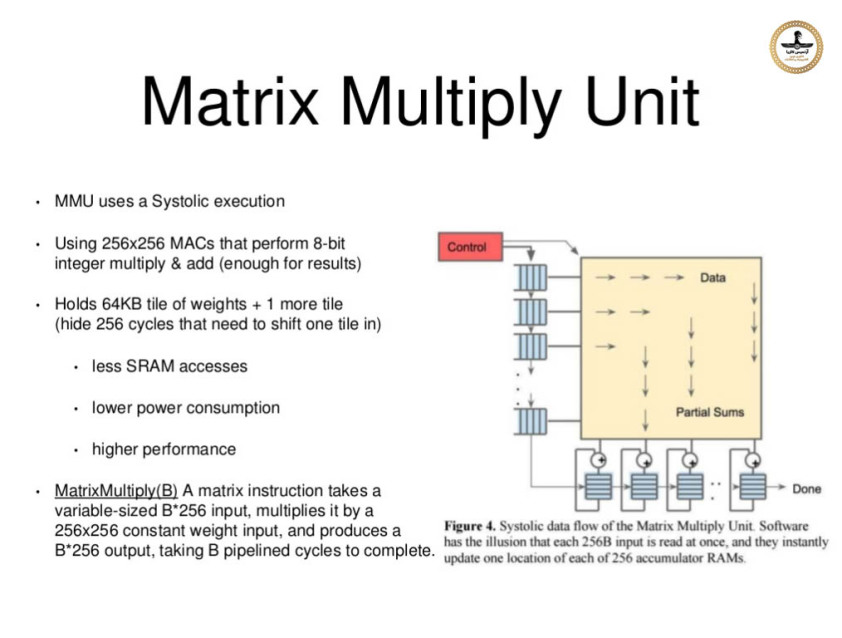
قلب "واحد پردازش تنسور" از واحـدی تشکیل شـده که دارای آرایـه ویژه ای است بنام "آرایه سیستولیک - systolic array" کـه شـامـل ماتریسـی خاص از داده ها است دارای 256×256 المــان 8 بیتی و یا بعبارت دیگر 64K الـمان 8 بیتل که هر یک از آنهـــا "ضرب کننده انباشتگرها" (MAC = Multiplyer-Accumulators) نام
دارد ، نــام بخشـی کـه آرایــه سیستـولــیک مــا در آن قــرار دارد "واحــد ضــرب
مـاتــریسی" (MMU = Matrix Multiply Unit) نــام دارد. ایـن بـخش بــه دو بــخش
دیـگر متصــل اسـت کــه یـکی بنـــام "انبــاشتــگرهــا" (Accumulators) اســت کــه
شامل 4096 × 256 المان 32 بیتی است و دومی بنام "بافر یکپارچه برای فعال سازهای محلی" (Unified Buffer for local Activations) شامل 24 مگابایت حافظه (MB24 =bit 8 × 256 ×K 96) می باشد. آرایه "ضرب کننده انباشتگرها" طوری تنظیم شده اند تا 256 نتیجه عملیاتی را در هر سیکل ساعت تولید کنند با تاخیری در خط لوله محاسباتی که بستگی به نوع دستورالعملی دارد که اجرا می شود. برخلاف سایر سیستم های محاسباتی که بر اساس بردارها و اعداد کار می کنند واحد پردازش تنسور گوگل بر اساس ماتریس ها کار می کند ، این واحد طوری طراحی شده که صزب های ماتریسی را در مقیاس بزرگ انجام می دهد. آرایه های سیستولیک بشکل سنگینی مسیردهی (Pipelined) شده اند ، عرض آرایه دارای 256 واحد است و المان ورودی به این آرایه در فاصله زمانی برابر 256 سیکل ساعت از آن خارج می شود. اگرچه در زمان اوج عملیات شما 65000 پردازشگر دارید که همه با هم بر روی پردازش داده ها کار می کنند.
بورد سخت افزاری "واحد پردازش تنسور" (TPU) که امکان اتصال به شکاف توسعه از نوع ساتا (SATA) در یک سرور را دارد اگرچه خود بورد از خط نقل و انتقال اطلاعات با استاندارد پی سی آی اکسپرس نسخه 3 و با سرعت 16 ایکس (PCIe Gen.3 x16) استفاده می کند.
شرحی کوتاه بر آرایه سیستولیک
در معماری محاسبه گرهای موازی ، یک آرایه سیستولیک شبکه ای است همگن از "واحدهای پردازش داده" (DPU = Data Processing Unit) که بطور فشرده به هم متصل شده اند و "سلول" و یا "گره" نامیده می شوند ، هر گره یا DPU به طور مستقل بخشی از نتیجه را به عنوان تابعی از داده های دریافت شده از جریان بالادستی خود محاسبه می کند ، نتیجه را در درون خود ذخیره می کند و آن را به پایین دست منتقل می کند. آرایه های سیستولیک توسط اچ ، تی کونگ و چارلز لیزرسون اختراع شدند که آرایه ها را برای بسیاری از محاسبات جبر خطی (محصول ماتریس ، سیستم حل معادلات خطی ، تجزیه LU ، و غیره) برای "ماتریس های باند" توصیف کرد.
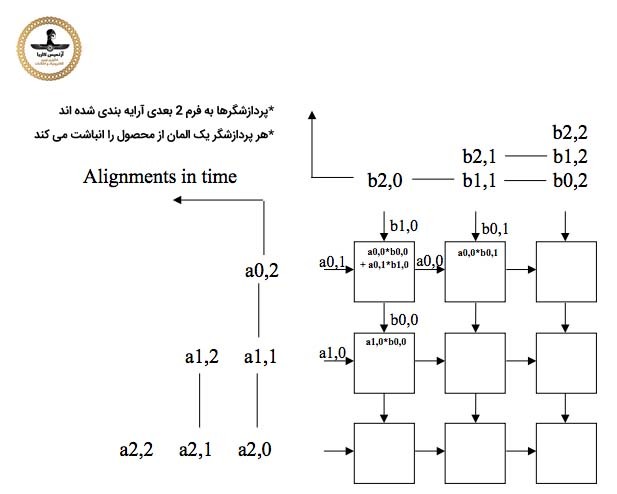
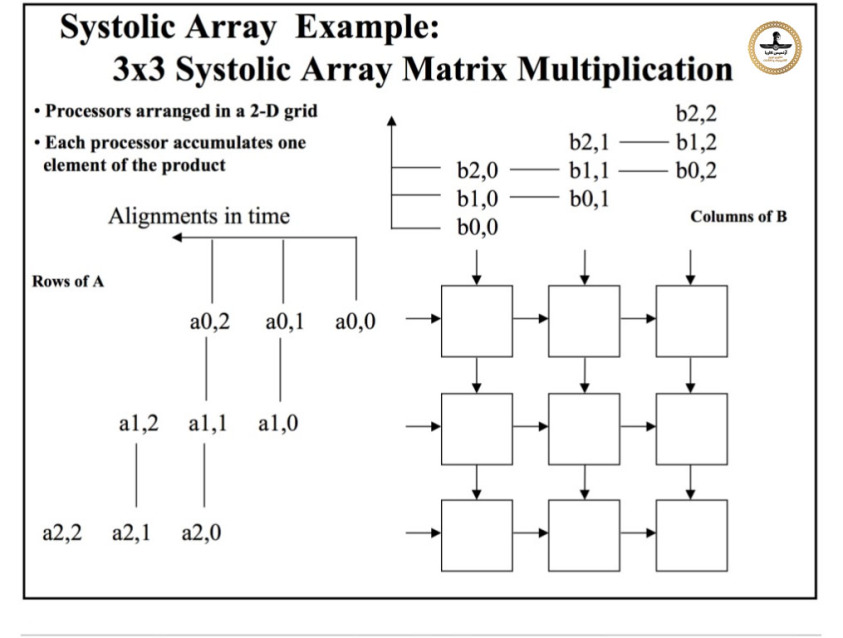
مثال آرایه سیستولیک
آرایه ماتریس ضرب سیستولیک 3×3
مزیت اصلی آرایه های سیستولیک این است که کلیه داده ها و یا اطلاعات مربوط به عملگــرها و اجــزاء نتایج در درون پردازشگر (حین عبور از آن) ذخیره می شوند. و در طی انجام عملیات نیازی به دسترسی به خط حامل های داده خارجی ، حافظه اصلی یا حافظه داخلی نیست بدلیل پیروی از قوانین ماشینهای متوالی (ترتیبی) "ون نومان" یا "هاوارد". محدودیت های توالی در عملکرد موازی توسط قانون Amdahl تعیین می شود و همیشه هم بمانند هم تعیین نمی شوند ، زیرا وابستگی و تبعیت داده ها برای اتصال داخلی به هم به طور ضمنی توسط "واحد پردازش داده" که قابل برنامه ریزی هستند تعیین می گردد و هیچ ترتیب پی در پی خاصی در مدیریت جریان داده های بشدت موازی با هم وجود ندارد. بنابراین ، آرایه های سیستولیک بسیار مناسب شبیه سازی اموری هستند که مغز موجودات آنها را بخوبی انجام می دهد بمانند هوش مصنوعی ، پردازش تصویر ، تشخیص الگوها ، بینایی ماشیــن و همچنین چنان
پردازشگرهایی بدلیل توانایی در پیکره بندی خودکار شبکه های عصبی مصنوعی سخت افزاری بسیار مناسب استفاده در سیستم های "فراگیری ماشین" هستند.
آرایه سیستولیک - چگونگی ورود داده ها به ماتریس و نحوه ضرب ماتریسها می شوند
شرح و بحث کامل مبحث آرایه های سیستولیک - بهار 2017 - دانشگاه زوریخ
استاد انور موتلو (Onur Mutlu)
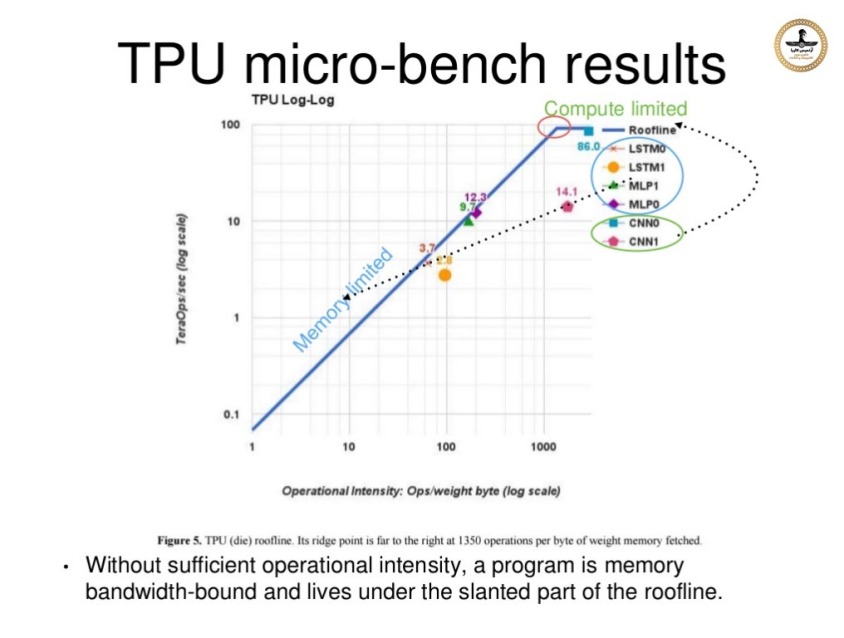
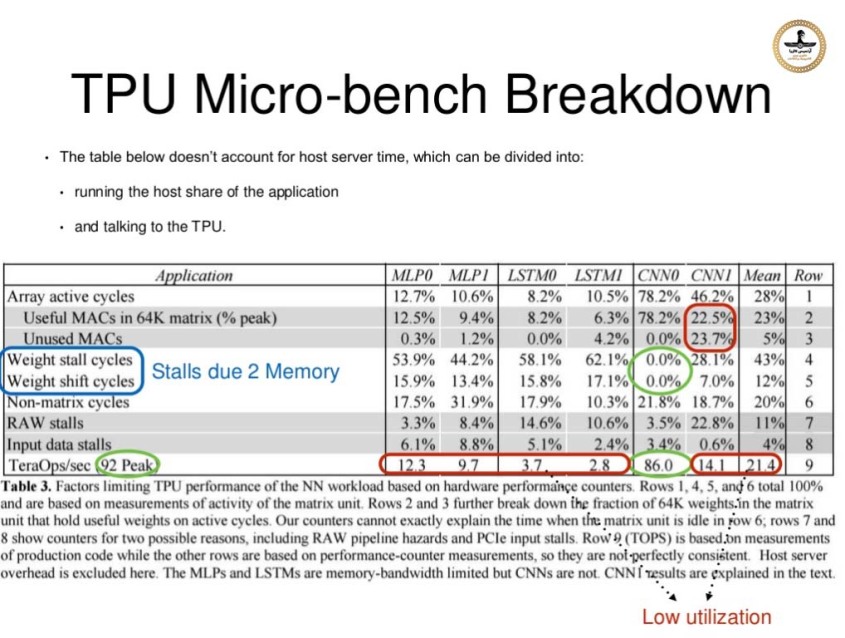
نکته جالب دیگر در مورد TPU این است که به نظر می رسد حـافظه DDR3 آن منحصراً بــرای داده هـای ویژه ایی که "وزن" (Weight) نام دارد و در حین عملیات "فراگیری ماشین" تولید می شوند ، استفاده می شود. دستورالعمل ها و داده های دیگر از طریق رابط "پی سی آی اکسپرس" وارد می شوند. مهندسین تلاش کردند تا در طراحی سخت افزار "واحد پردازش تنسور" سازگاری لازم را با زیرساخت های موجود از قبل را حفظ کنند ، بنابراین آنها TPU را طوری طراحی کردند تا در درگاه های اتصال استاندارد هارد دیسک های سرور 3.5 اینچی قرار بگیرند و از سوی دیگر و از طریق یک رابط اتصال "PCIe Gen 3.0 x16" سایر اطلاعات به TPU نقل و انتقال پیدا می کنند .گوگل همچنین چهار واحد TPU را برای هر سرور اختصاص داد تا بتواند از پس بارهای سنگین محاسبات فشرده بر آید. طراحی قلب TPU تراشه ایی است که با فناوری ساخت 28 نانومتری ساخته شده است و همانطور که قبلا گفته شد به صورت ASIC طراحی شده یعنی این سخت افزار صرفا برای اجرای یک برنامه کاربردی خاص ساخته شده و تا آنجا که می دانیم اینگونه سخت افزارها معمولا تا 40 وات توان مصرف می کنند. فرکانس کار آن هم 700 مگاهرتز می باشد ، در "واحد ضرب ماتریس" آن که دارای 256×256 المان است صدها هزار عملیات در هر سیکل ساعت پردازش می شوند که بسیار بیشتر از پردازنده های عمومی و گرافیکی است.
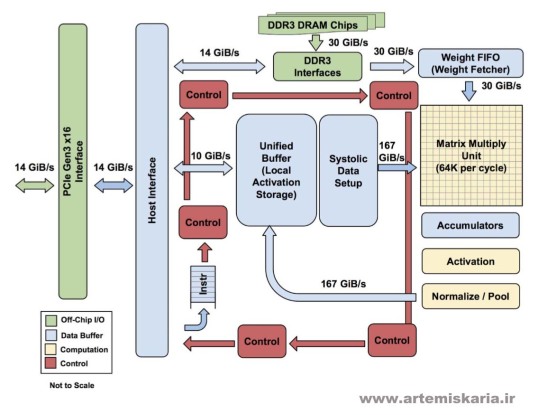
در این تصویر بلوک دیاگرام "واحد پردازش تنسور" نسخه یک را ملاحظه می کنید ،قسمت اصلی محاسباتی در مربع زرد رنگ بالا سمت راست بنام "واحد ضرب ماتریس" واقع شده و ورودی آن از بالا داده هایی بنام "وزن - Weight" هستند که با روش "اولین در ورود - اولین در خروج" یا همان FIFO وارد ماتریس می شوند ، همچنین داده های دیگری از سمت چپ و از واحدی بنام "بافر یکپارچه" وارد ماتریس می شوند ، خروجی ماتریس از سمت پایین به واحدی بنام انباشتگر ها (Accumulators) است و از آنجا داده های خروجی وارد واحدی بنام "فعال ساز" (Activation) می شوند که در آنجا بر روی انباشتگرها توابع غیر خطی اجرا می شوند. و در ادامه اطلاعات دوباره وارد واحد "بافر یکپارچه" می گردند.
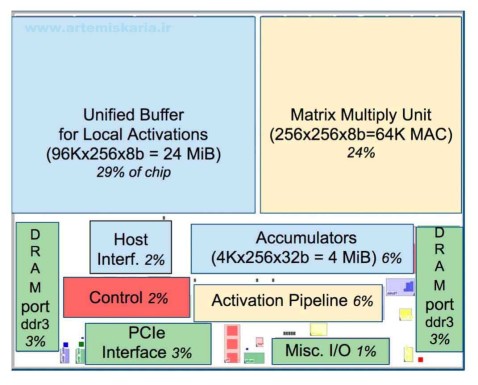
در این تصویر نقشه زمینه تراشه TPU نسخه یک بنمایش آمده و مشخص شده هر واحد چند درصد از مساحت تراشه را بخود اختصاص داده و همچنین ظرفیت واحدهایی که دارای ماتریس و حافظه اطلاعات هستند مشخص شده.
ویژگیهای دیگر TPU
واحد MMU دارای 256×256 = 65536 المان 8 بیتی بنام "انباشتگرهای ضرب یا MACs.
فرکانس کار 700 مگاهرتز می باشد
قدرت عملیاتی برابر است با 92 ترا عملیات در ثانیه = 65536×2×700M
25 برابر سریعتر از پردازنده های گرافیکی
100 برابر سریعتر از پردازنده های رایانه ها
4 مگابایت حافظه داخل تراشه برای انباشتگرها
24 مگابایت حافظه داخل تراشه برای "بافر یکپارچه"
دارای 3.5 برابر حافظه بیشتر نسبت به تراشه های گرافیکی
2 کانال انتقال اطلاعات از نوع DDR3-2133MHz
8GB حافظه خارج از تراشه برای ذخیره اطلاعات " وزنها - Weights"
هدف از ساخت
درخواست های جستجو در اینترنت
مترجم هایی که از ماشین های دارای شبکه عصبی مصنوعی استفاده می کنند
حوزه فرا گیری ماشین و هوش مصنوعی

شرحی بر واحد پردازش تنسور در سرورهای گوگل و نقش آن در فراگیری ماشین توسط کلیف یانگ (برنامه نویس ارشد در کارگروه "مغزگوگل") و دیوید پاترسون (برکلی و گوگل)
تاریخچه "واحد پردازش تنسور" (TPU) و شرحی بر عملکرد سخت افزار آن






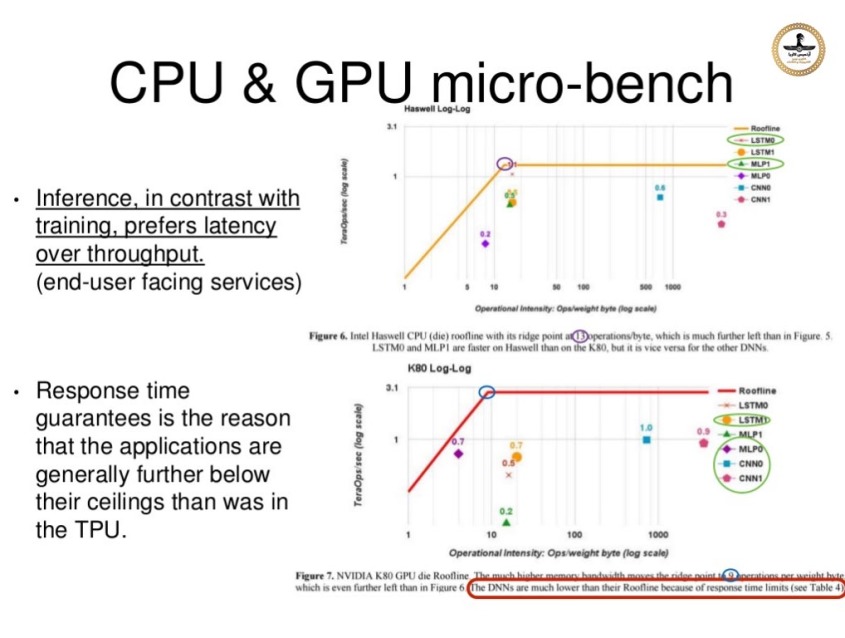


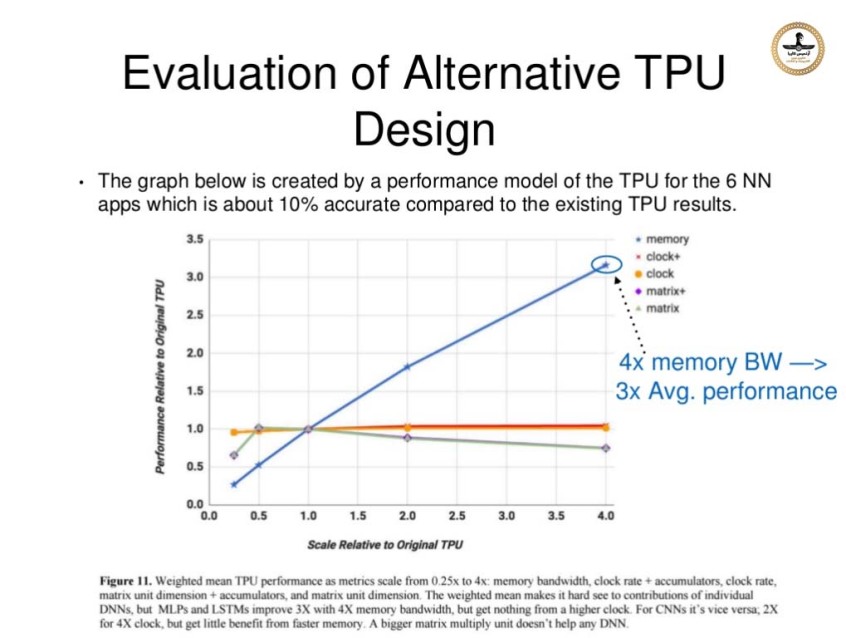
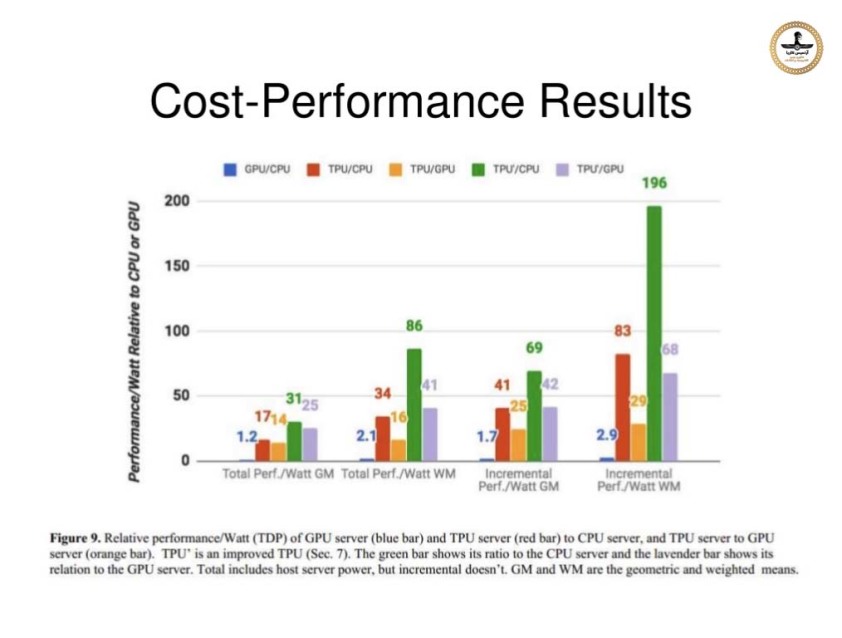


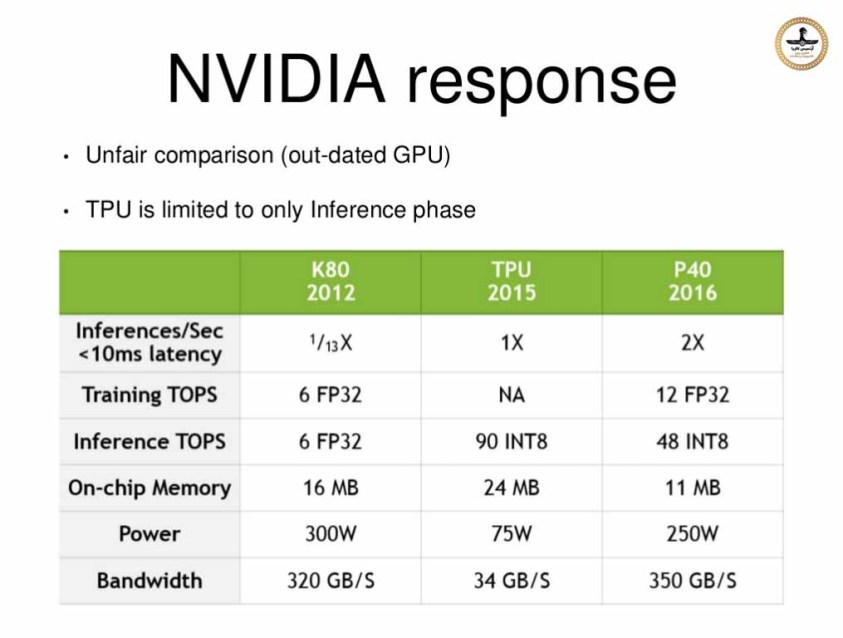
بازدید کننده گرامی برای مشاهده این تارنما گوشی همراه و یا تبلت خود را در وضعیت "Desktop site" قراردهید.
برای انتخاب "Desktop site" به منوی مرورگر رجوع کنید. (در مرورگر کروم این منو در بالا سمت راست با علامت سه نقطه قرار دارد)


تماس با ما :

ثبت نام برای دسترسی به صفحه محصولات

تلفن واحد فروش : 02140883165 (داخلی یک)



تلفن واحد فروش (سازمانها و نهادها): 09902157178
sales@artemiskaria.ir
